Analyzing Music Data using PySpark


Project information
- Category: Big Data Analytics
- Project date: Feb 01, 2021
- Project URL: GitHub Repository
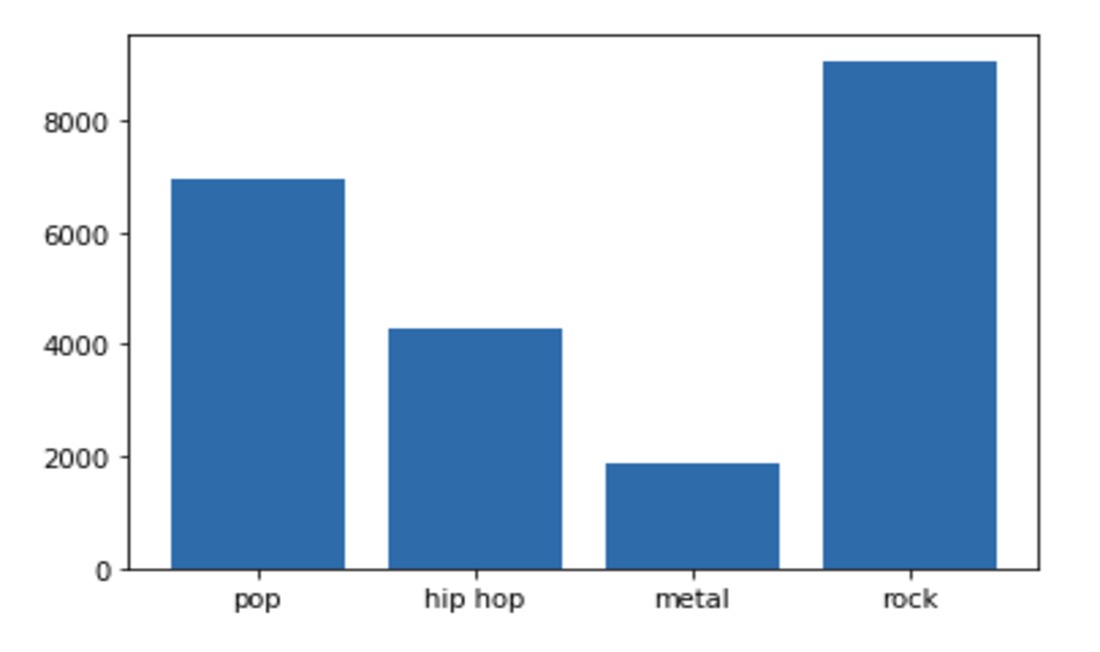
This is an introductory project to PySpark and PySpark SQL. The goal of the project is to get familiarized with building a Spark session, loading data, transforming it, and finally querying it.
There are 2 datasets: listening.csv and genre.csv.
- listening.csv is a collection of songs that Users of LastFM have listened to.
- genre.csv contains the genre of every major artist who is present in the listening.csv file.
Data Source: Google Drive